Index fun
Elements on web pages are mostly side-by-side, or above and under each other. Occasionally however, a design calls for two or more elements to overlap. Familiar examples include unfolding navigation menus, preview panes when hovering a link, unhelpful banners about cookies, and of course countless popups demanding your immediate attention.
How I became great at everything
A tale of courage, guile, and unsupported assertions.

It was December in Bali. I was dozing off when the Slack notification jolted me awake. I felt an unfamiliar pull, and for the first time, I looked not at the bouncing icon, but over the lotus-covered pond, and straight into the glistening sea; I was living life wrong.
My relentless pursuit of perfection had taken a toll. Running three companies was pushing me to my limits; I had been forced on multiple occasions to pull a 5- or even 6-hour work week. The Hindu temples I had come to surround myself with were whispering to me. The language was foreign and the voice indecipherable, but the message was crystal clear:
Pardon the interruption.
z-index values determine which one is shown on top.In these situations, the browser must somehow decide which elements to draw “on top”, and which elements to keep in the background, fully or partially covered. A relatively complex1 set of rules in the CSS standard defines a default stacking order for every element in a page.
When the default order is unsatisfactory, developers resort to the z-index property: it gives control over a virtual z axis (depth), defined conceptually as going “through” the page. An element with a higher z-index is thus displayed “closer” to the user, that is, painted on top of elements with lower indices.
An interesting property of the z axis is that it does not have natural bounds. The horizontal and vertical axes are typically restricted by the expected dimensions of the display. We would not expect any elements to be positioned “1000000px from the left” or “-3000em from the top”: they would either be invisible, or incur unpleasant amounts of scrolling.2 Values for z-index however are unitless, and only matter in relative terms: a page with two elements will look the same if the z indices are 1 and 2, or -10 and 999. This, combined with the fact that pages are often assembled from components developed in isolation, leads to the curious art of picking appropriate z indices.
How do you make sure your annoying popup is shown on top of every other element in the page, when you don’t know how many there are, who wrote them, and how bad they wanted their elements to be on top? That’s when you set your z-index to 100, or maybe 999, or maybe, just maybe 99999 to be really sure yours will win.
That, at least, is how I write my CSS. In the rest of this post, we will look at millions of z indices to see what everyone else does.
Getting the data
The first step was to acquire a large set of z-index values from existing webpages. For this I turned to Common Crawl, a publicly available, very large, and wonderful repository of pages crawled from the web. The data is hosted on S3, meaning that it is reasonably efficient to query it from an AWS cluster, and there are fortunately multiple tutorials online showing how to do just that.
My elaborate z-index extractor consists in finding, in every page, all matches of the following regular expression:
re.compile(b'z-index *: *(-?[0-9]+|auto|inherit|initial|unset)')
Once the values are identified, we are left with a standard word-count map-reduce task. Luckily, I’m not the first person who wants to count occurrences of things, and it was enough to adapt one of many examples. (Almost all my original code is the regex above.)
With the help of a very detailed blog post, I deployed the code on an Elastic Map Reduce cluster, and proceeded to scan through pages from the March 2019 crawl archive. That specific snapshot is organized into 56,000 parts, from which I picked 2,500 at random, or about 4.4%. There is nothing special about that number, other than it translated roughly into the cost I was willing to invest in this experiment. After a terrifying night hoping that I had done my projections correctly, I had my results, extracted from 112.7M pages.3
Most common indices
My scan yielded a total of about 176.5M z-index values, split across 36.2K unique values.
So what are the most common ones?
Figure 1 shows the top 50. Note that the y axis uses a log scale, and shows relative frequencies. For instance, the most common value, 1, accounts for 14.6% of all occurrences found across the sample. Together, the top 50 account for around 80% of all collected values.
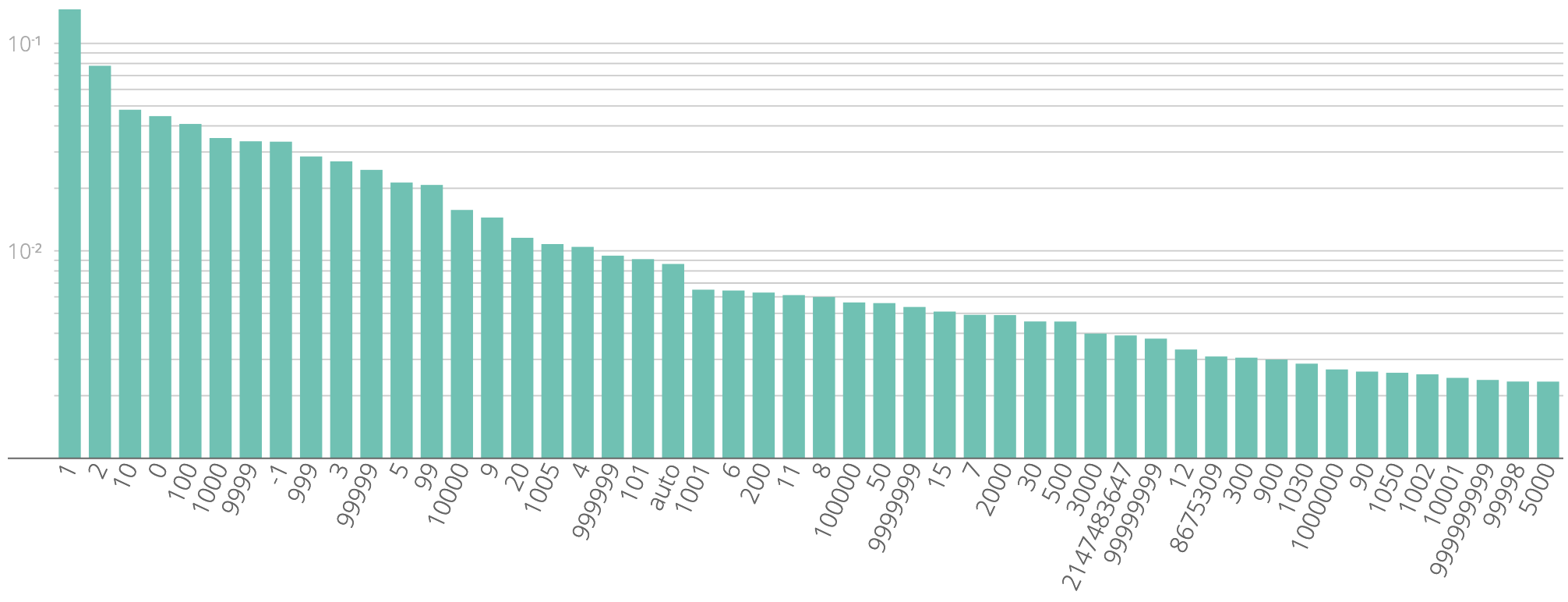
z-index values. The y axis shows the relative frequency.The first observation is that positive values dominate: the only negative one in the top 50 is -1. (The second most-common one, -2 ranks 70th.) This maybe tells us that people are generally more interested in bringing things to front than hiding them in the back.
Generally, most of the top values have one of the following properties:
- They are small: e.g. all the ordinals from
0to12are in the top 50. - They are powers of ten, or multiples of power of tens:
10,100,1000,2000, … - They are “close” to a power of ten:
1001,999,10001, …
These patterns are consistent with humans picking large “familiar” values (powers of ten), and then, possibly to adjust relative depths within a component, values slightly above or under them.
It is also interesting to look at the most common values that do not fit any of these patterns:
At rank 36, we have 2147483647, a number that many programmers will instantly recognize as INT_MAX, or 231-1. The thought process must be that, since this is the largest value a (signed) integer can have, no z-index can possibly be higher and thus an element with index INT_MAX will always be on top. MDN however has this to say about integers in CSS:
There is no official range of valid
<integer>values. Opera 12.1 supports values up to 215-1, IE up to 220-1, and other browsers even higher. During the CSS3 Values cycle there was a lot of discussion about setting a minimum range to support: the latest decision, in April 2012 during the LC phase, was [-227-1; 227-1], but other values like 224-1 and 230-1 were also proposed. However, the latest spec doesn’t specify a range anymore.
So not only is there no agreed upon max value, but in every documented specification or standard proposal, INT_MAX is in fact out of range.
At rank 39, we have 8675309, which I personally didn’t recognize as being particularly noteworthy. However, with over half a million collected uses, it clearly is meaningful to many. I suspect it is either instantly recognizable or completely obscure, depending on where and when you grew up. I won’t spoil it for you, the answer is just one search away.
The last two numbers that seemed a little out of place are 1030 and 1050, at ranks 42 and 45 respectively. Another cursory web search showed that these are the default z-index values for Bootstrap’s navbar-fixed and modal classes, respectively.
Value distribution
Even though a small set of common values account for the vast majority of all z indices, it can be interesting to look at the broader distribution of the collected set. For instance, Figure 2 shows the frequency of all values between -120 and 260.
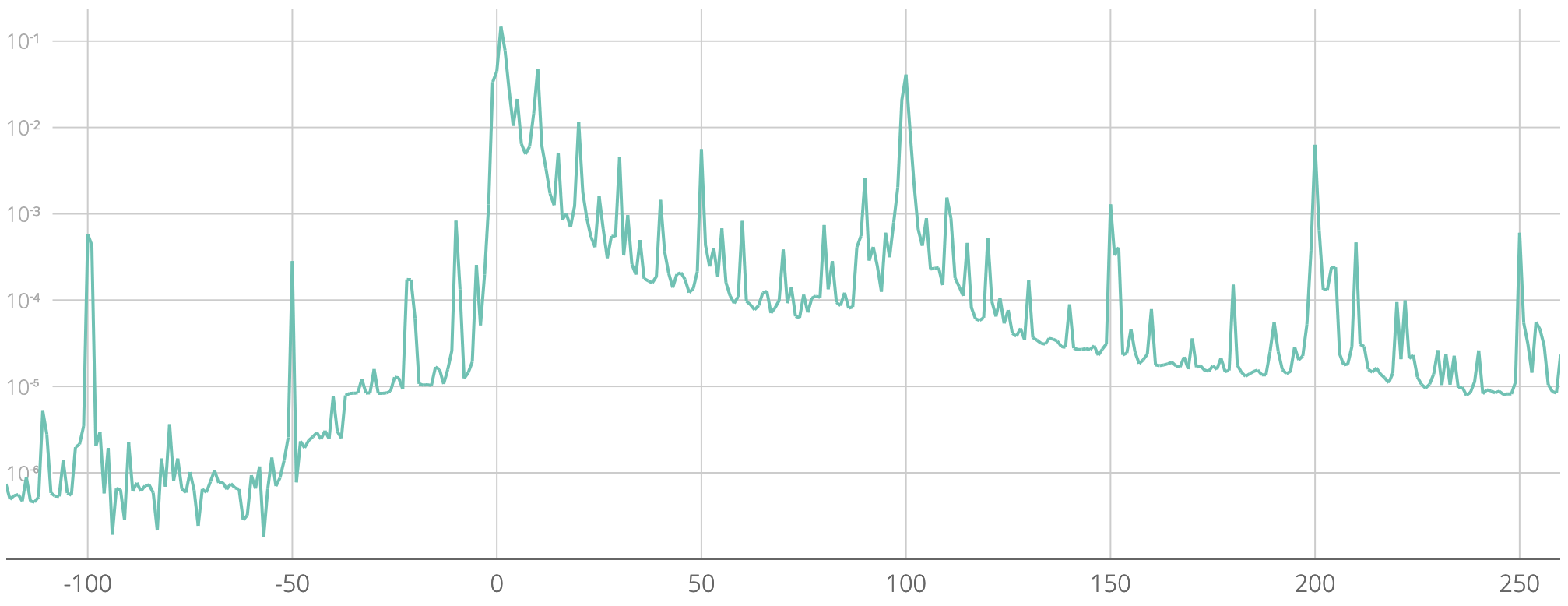
z-index values from -120 to 260.In addition to the dominance of round numbers, we see an almost fractal-like quality, with patterns visible at multiple frequencies. For instance, the midpoint between two local maxima is itself a (lower) maximum: 5 between 1 and 10, 15 between 10 and 20, 50 between 1 and 100, etc.
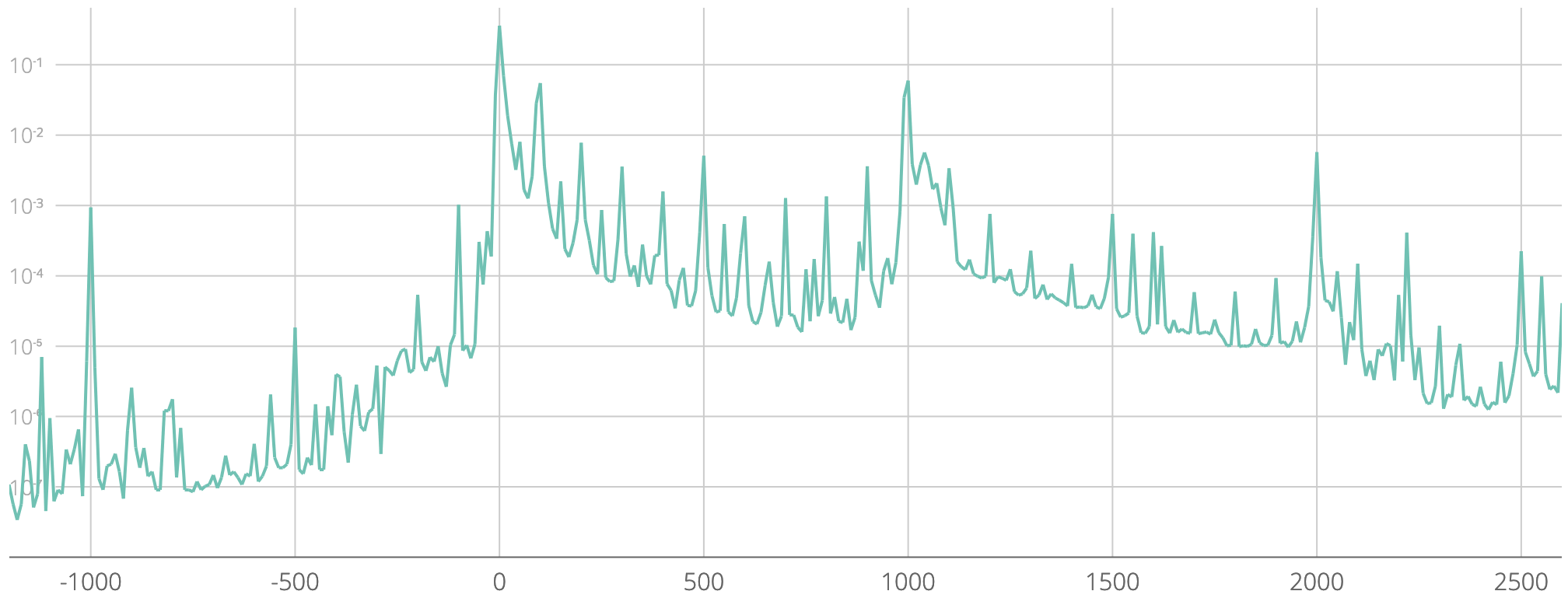
We can confirm this effect by considering a wider range: Figure 3 shows the frequencies of all values from -1200 to 2600, ignoring the last digit. That is, the frequencies of e.g. 250, 257, and 259 are summed up and shown as a single point with x = 250. The graph is remarkably similar to Figure 2, showing that most of the structure of the distribution is preserved when considering values an order of magnitude larger.
z-index values from -1200 to 2600, grouped by ignoring their least significant digit.Finally, Figure 4 shows all positive z-index values between 1 and 9999999999 grouped by their first digit (horizontal axis) and the number of digits (vertical axis).
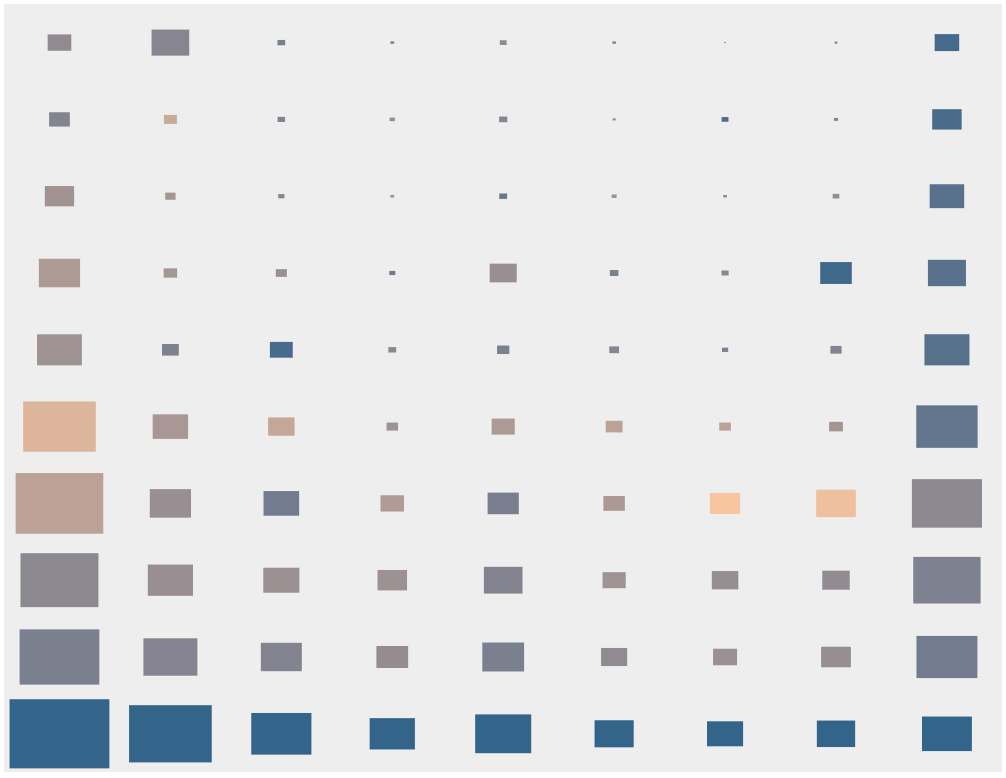
z-index values grouped by first digit and number of digits. Sizes are proportional to the group total frequency. Click or tap on a group for details.We can intuitively think of a group as a pattern of values, e.g. 3xxx for four-digit values starting with 3. Each group is shown as a rectangle whose size is proportional to the frequency of the pattern. The figure shows, for instance, that for each order of magnitude, i.e. row of groups, the frequencies follow a similar trend, with the values starting with 1 being the most common, then 9, then 5.
The hue of each group is assigned based on its entropy, a measure of the diversity of values within the group. Yellow groups have the highest, and blue groups have the lowest entropy. This helps highlight the patterns among which developers tend to select the same values, and the ones where they pick less uniformly. (Note that the entropy for the entire dataset is 6.51 bits.)
You can click (or tap) on each group to see the top 3 values within in, and their frequency relative to the group. Can you spot the pop culture references?
Conclusion
While it was definitely fun to collect and explore this data set, I’m sure there are better statistics, visualizations, and explanations waiting to be mined and presented. If you’d like to give it a try, feel free to download and share the z-index count file.
Perhaps you will succeed where I failed, and find a way to include in a chart the largest z-index value I found, namely 101242-1.
Yes, that’s the number 9 repeated 1242 times. I really hope they were finally able to show their <div> on top.
-
Arguably everything is relatively complex, but it is not particularly encouraging that the standard comes with a dedicated appendix entitled “Elaborate description of Stacking Contexts”. ↩
-
Unless you are reading this post at a time where multi-million-pixel-wide displays are common. If that is the case, I encourage you to stop reading and go start the Trillion Dollar Webpage project instead. ↩
-
I should note that these are all HTML pages. I did not dig into this question too much, but it appears that Common Crawl does not index external stylesheets, and as a result I only extract values from inline CSS. We leave as an exercise to the reader to determine whether the resulting distribution matches what you would get from external stylesheets. ↩